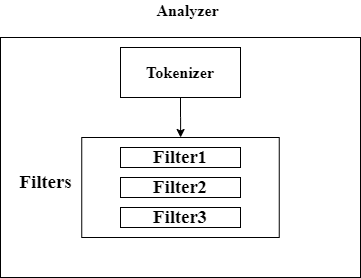
tokenizer 和 analyzer 的关系
Tokenizer、Token-filter 和 analyzer:
- tokenizer:分词器
- analyzer:分析器
- token-filter:分词过滤器
1、Tokenizer(分词器)
分词,就是将一个字符串,按照某种特定规则打散为多个字符串的过程。
2、Token-filter(分词过滤器)
分词过滤器,是对分词器处理后得到的子字符串,进行字符的修改。 (例如:大小写转换、时态、复数……)
3、Analyzer(分析器)
分析器是分词器和分词过滤器的结合。
ES 使用分析器(Analyzer)对文档进行分词,ES 中内置了很多分析器供我们使用,我们也可以定制自己的分析器。
一个分析器有 3 个组成部分,分析过程会依次经过这些部分:
- Character Filters:字符过滤,用于删去某些字符。该组件可以有 0 或多个。
- Tokenizer:分词过程,按照某个规则将文档切分为单词,比如用空格来切分。该组件有且只能有一个。
- Token Filter:对切分好的单词进一步加工,比如大小写转换,删除停用词等。该组件可以有 0 或多个。
也就是说,分词器就是划分子字符串,分词过滤器就是子字符串的格式转换,分析器是两者结合。