本文是一篇英文翻译转载文章,主要介绍了向量嵌入的一些基础知识。
原英文链接:https://www.pinecone.io/learn/vector-embeddings-for-developers/
你可能还不知道,但是向量已经嵌入无处不在。它们是许多机器学习和深度学习算法的基石,从搜索到人工智能助手等应用程序都是用这些算法。如果你正在考虑在这些领域中构建自己的应用程序,那么未来你可能会遇到向量嵌入。在这篇文章中,我们将尝试介绍向量嵌入是什么以及如何使用它们。
我们要解决什么问题?
在构建传统应用程序时,数据结构表示为可能来自数据库的对象。这些对象具有与你正在构建的应用程序相同的属性(或数据库中的列)。
随着时间的推移,这些对象的属性数量不断增强,以至于你可能需要更加谨慎地选择完成给定任务所需的属性。你甚至可能最终构建这些对象的专门表示来解决特定的任务,而不必支付必须处理非常“胖”的对象开销。这个过程被称为特征工程(Feature Engineering)——通过只挑选与手头任务相关的基本特征来优化应用程序。
当你处理非结构化数据时,你将不得不经历相同的特征工程过程。然而,非结构化数据可能有更多相关特征,而执行手动特征工程注定是不可行的。
在这些情况下,我们可以使用向量嵌入作为一种形式的自动特征工程。我们不再从数据中手动挑选所需的特征,而是应用一个预先训练好的机器学习模型,该模型将生成一个更紧凑的数据表示,同时保留数据的有意义之处。
什么是向量嵌入?
在我们深入研究向量嵌入之前,让我们先讨论一下向量。向量是一种具有大小和方向的数据结构。例如,我们可以把向量看作空间中的一个点,“方向”是从 (0,0,0) 到向量空间中该点的箭头。
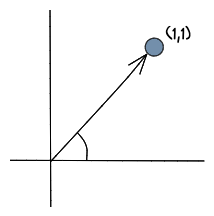
作为开发人员,可能更容易把向量想象成一个包含数值的数组。例如:
1 | vector = [0,-2,...4] |
但我们在一个空间中观察一组向量时,我们可以说是有些向量彼此接近,而有些则相距甚远。一些向量似乎可以聚集在一起,而其他向量可以稀疏地分布在空间中:
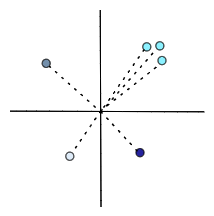
我们将很快探索向量之间的这些关系是如何有用的。
向量是机器学习算法的理想数据结构——现代 CPU 和 GPU 都进行了优化,以执行处理它们所需的数学运算。但是我们的数据很少用矢量表示。这就是向量嵌入发挥作用的地方。这种技术允许我们获取几乎任何数据类型,并将其表示为向量。
但是这不仅仅是把数据转换为向量那么简单。我们希望确保能够在转换后的数据上执行任务,而不会丢失数据的原始含义。例如,如果我们要比较两个句子——我们不仅要比较它们所包含的单词,而且要比较它们是否意味着同一件事。为了保持数据的含义,我们需要了解如何在向量之间的关系有意义的地方生成向量。
要做到这一点,我们需要一个所谓的嵌入模型。许多现代嵌入模型都是通过将大量的标记数据传递给神经网络来建立的。你可能以前听说过神经网络——它们是用来解决各种复杂问题的流行算法。用非常简单的术语来说,神经网络是由函数连接的节点层组成的;然后我们训练这些神经网络来执行各种任务。
我们通过监督式学习训练神经网络——向神经网络提供由成对输入和标记输出组成的大量训练数据。或者,我们可以应用自我监督或非监督式学习,其中任何一个都不需要标记输出。这些值通过网络激活和操作的每一层进行转换。通过每次迭代训练,神经网络修改每一层的激活。最终,它可以预测给定输入的输出标签应该是什么——即使它以前从来未见过这种特定输入。
嵌入模型基本上是去掉最后一层的神经网络。我们得到的不是输入的特定标记值,而是向量嵌入。
嵌入模型的一个很好的例子是流行的 word2vec,它经常用于各种基于文本的任务。让我们看看 TensorFlow 的投影仪工具产生的可视化,它使嵌入更容易可视化。
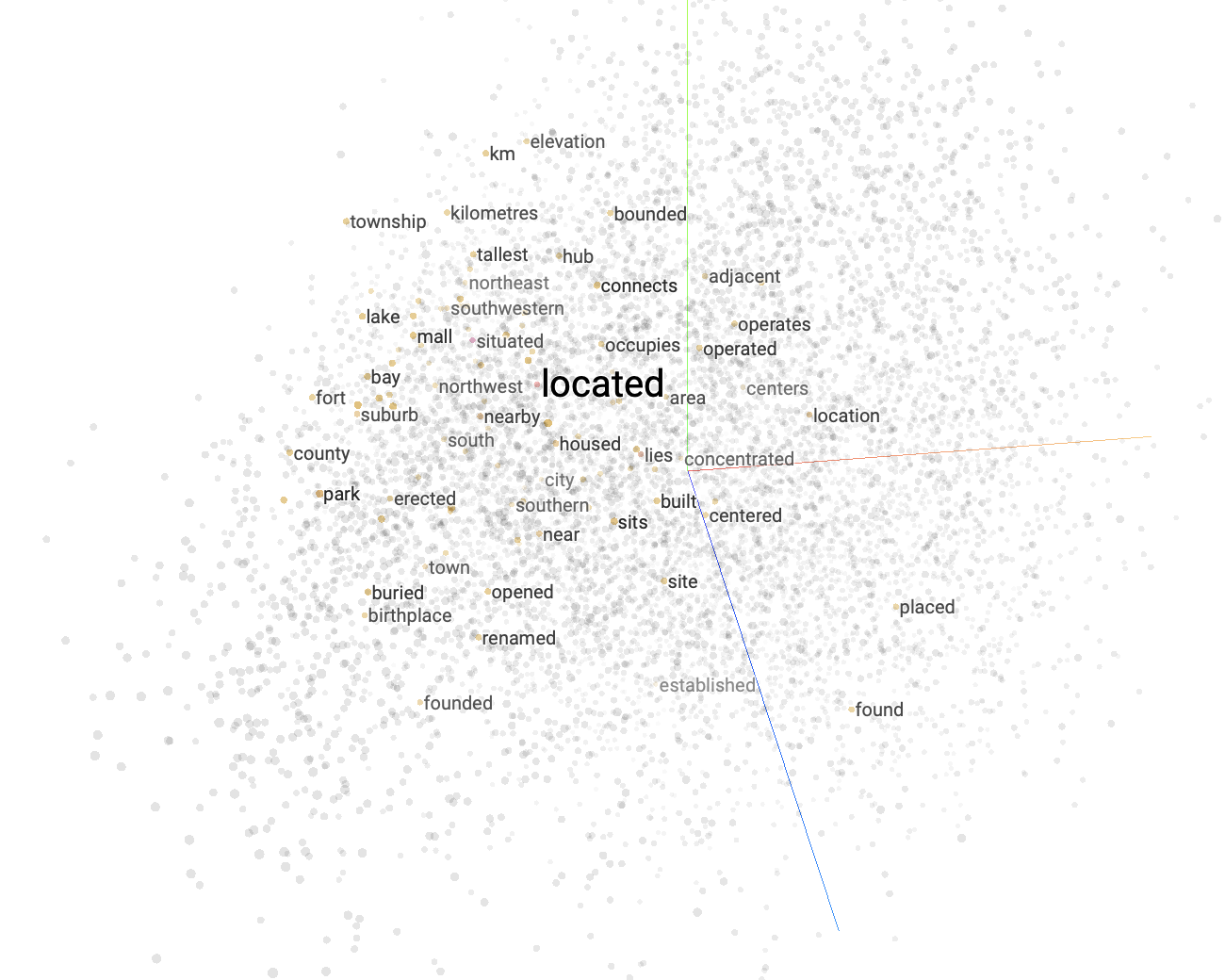
尽管这种可视化只表示嵌入的三个维度,但它可以帮助我们理解嵌入模型是如何工作的。可视化中突出显示了多个数据点,每个数据点表示一个单词的向量嵌入。顾名思义,word2vec 嵌入了单词。相邻的词语在语义上是相似的,而相距较远的词语在词义上是不同的。
经过训练,嵌入模型可以将原始数据转换为向量嵌入。这意味着它知道在向量空间中放置新的数据点。
正如我们在 word2vec 中看到的,在模型的上下文中,紧密相连的向量具有上下文相似性,而相距较远的向量彼此不同。这就是赋予向量意义的东西——它与向量空间中其他向量的关系取决于嵌入模型如何“理解”它所训练的领域。
我能用向量嵌入做什么?
向量嵌入是一个非常通用的工具,可以应用于许多领域。一般来说,应用程序会使用一个向量嵌入作为它的查询,并产生其他类似的向量嵌入,其相应的值。每个领域的应用程序之间的差异就是这种相似性的重要性。
下面是一些例子:
- 语义搜索:传统的搜索引擎通过搜索关键字的重叠来工作。通过利用向量嵌入,语义搜索可以超越关键词匹配,基于查询的语义进行查询。
- 问答应用程序:通过训练一个嵌入式模型,其中包含成对的问题和相应的答案,我们可以创建一个应用程序来回答以前从未见过的问题。
- 图像搜索:向量嵌入非常适合作为图像检索任务的基础。有多种现成的模型,如 CLIP、 ResNet 等。不同的模型可以处理不同类型的任务,比如图像相似性、目标检测等等。
- 音频搜索:通过将音频转换成一组激活(音频光谱图) ,我们生成可用于音频最近邻搜索的向量嵌入。
- 推荐系统:我们可以创建嵌入的结构化数据,关联到不同的实体,如产品,文章,等。在大多数情况下,你必须创建自己的嵌入模型,因为它是特定于你的特定应用程序的。有时,当找到图像或文本描述时,这可以与非结构化嵌入方法结合使用。
- 异常检测:我们可以创建嵌入异常检测使用标记传感器信息的大数据集,识别异常事件。