HDF5 文件转 vecs 文件
HDF5 文件的结构
一个 HDF5 格式的文件是一个包含两个对象的容器,一个是数据集(datasets),另一个是组(groups)。数据集的结构非常类似于 Numpy 的 array,组的结构非常类似于 python 的字典,它像一个文件夹一样,它可以包含数据集和其它的组。总结起来:组像字典一样工作,数据集像 NumPy 数组一样工作。
拿 HDF5 格式数据集 gist-960-euclidean.hdf5 为例(下载地址),整个文件有一个根组,就是下图的”/“。
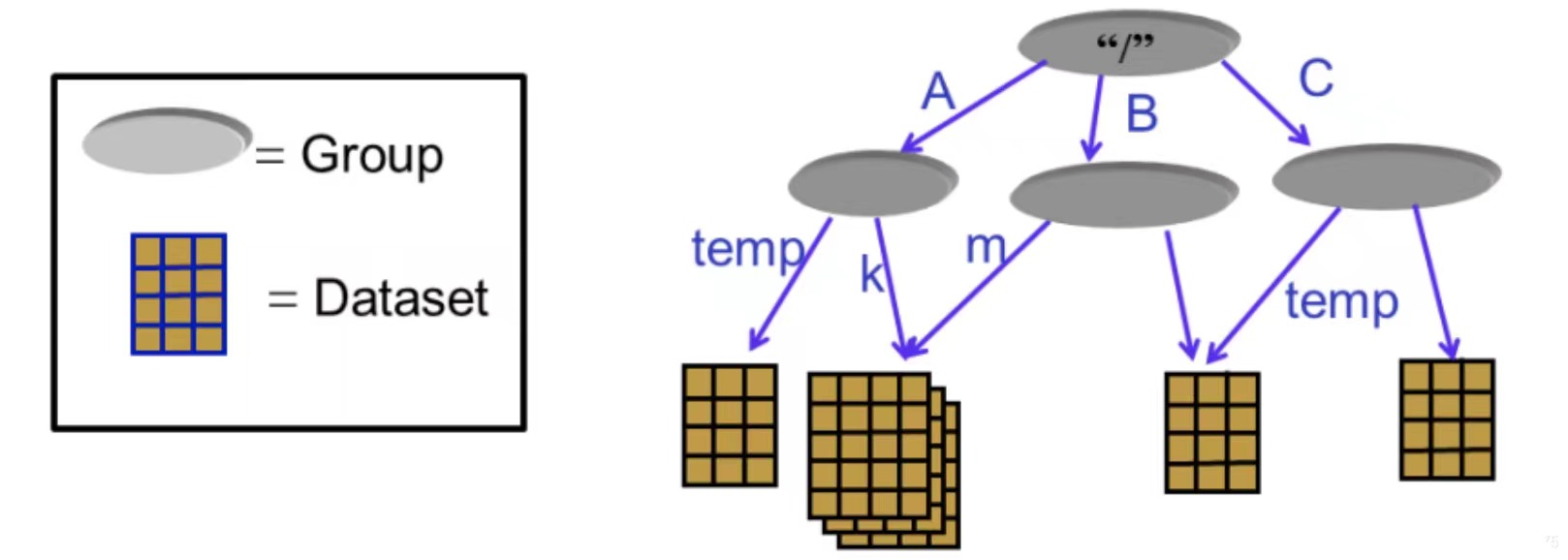
根组下有四个键,分别为 distances、neighbors、test 和 train,类比于上图中的 A、B 和 C。
- distances 对应的是 shape 为 (1000, 100) 的数据集(类比于 Numpy 的 array),为每个查询向量最近的 100 个向量距该查询向量的距离,数据类型为 float32
- neighbors 对应的是 shape 为 (1000, 100) 的数据集,为每个查询向量最近的 100 个向量,数据类型为 int32
- test 对应的是 shape 为 (1000000, 960) 的数据集,这是基数据(原始数据),一共 1000000 个向量,每个向量的维度为 960 维,数据类型为 float32
- train 对应的是 shape 为 (1000, 960) 的数据集,只是查询数据,一共 1000 个向量,向量的维度为 960 维,数据类型为 float32
vecs 文件的结构

在常用的公开数据集中,数据集文件、查询文件往往使用 fvecs 格式存储。而真值集(即查询的答案)文件使用 ivecs 格式存储。其实这两种格式十分相似。
fvecs
数据集、查询集采用fvecs格式,其实他们是完全相同的东西。在数据集中,存储的是所有向量,而查询集中,存储的同样是向量,只是向量数量会少一些。
fvecs 采用二进制来存储,直接打开便是乱码。
下面用一张图来表示 fvecs 的大致格式:
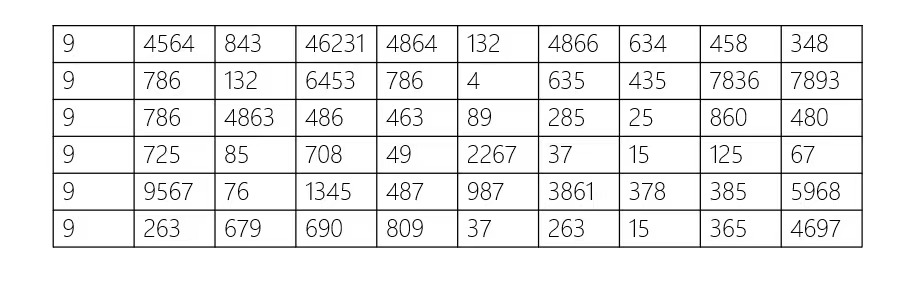
每一“行”中,第一个数表示数据的维度 dim,后面跟着的 dim 个数便是向量各维度的值。(注:fvecs 中的 f 指 float32)
因此,一“行”表示的便是一个向量。
ivecs
ivecs 其实和 fvecs 的格式是一样的,只不过它存储的不是向量,而是每一条查询的答案。
就是说,ivecs 里的每一“行”里,第一个数据是查询答案的数量 n,后面 n 个数是答案向量的 id。(注:ivecs 中的 i 指 int32)
HDF5 转 vecs 脚本
'''
Author: pudding
Date: 2024-02-02 10:15:39
'''
import argparse
import os
import h5py
import numpy as np
import struct
import sklearn.preprocessing
def load_hdf5_file(filename):
print('loading:'+ filename)
hdf5_f = h5py.File(filename, 'r')
print('load done !')
return hdf5_f
def to_fvecs(filename, data):
with open(filename, 'wb') as fp:
for y in data:
# 将 y.size(dim) 以 C++ 的 unsigned int 的形式写入二进制文件
d = struct.pack('I', y.size)
fp.write(d)
for x in y:
# 将 x(vector)以 C++ 的 float 的形式写入二进制文件
a = struct.pack('f', x)
fp.write(a)
def to_ivecs(filename, data):
with open(filename, 'wb') as fp:
for y in data:
d = struct.pack('I', y.size)
fp.write(d)
for x in y:
a = struct.pack('I', x)
fp.write(a)
def run(file_path):
dataset = load_hdf5_file(file_path)
dimension = int(dataset.attrs["dimension"]) if "dimension" in dataset.attrs else len(dataset["train"][0])
print('======== HDF5 Basic Information ========')
print('dataset dimension:'+ str(dimension))
filename = file_path.split('/')[-1]
dataname = filename.split('.')[0]
X_train = np.array(dataset["train"])
X_test = np.array(dataset["test"])
distance = dataset.attrs["distance"]
# if distance == "angular":
# X_train = sklearn.preprocessing.normalize(X_train, axis=1, norm="l2")
# X_test /= np.linalg.norm(X_test)
print("Dataname:" + dataname)
print("distance:", distance)
print("got a train set of size (%d * %d)" % (X_train.shape[0], dimension))
print("got %d queries" % len(X_test))
print('======== HDF5 to vesc ========')
dataset_dir = os.path.join('./vecs', dataname)
if not os.path.exists(dataset_dir):
os.makedirs(dataset_dir)
to_fvecs(os.path.join(dataset_dir, dataname+'_base.fvecs'), X_train)
to_fvecs(os.path.join(dataset_dir, dataname+'_query.fvecs'), X_test)
to_ivecs(os.path.join(dataset_dir, dataname+'_groundtruth.ivecs'), dataset['neighbors'])
print("dataset['train'] to "+ str(os.path.join(dataset_dir, dataname+'_base.fvecs')))
print("dataset['test'] to "+ str(os.path.join(dataset_dir, dataname+'_query.fvecs')))
print("dataset['neighbors'] to "+ str(os.path.join(dataset_dir, dataname+'_groundtruth.ivecs')))
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Run the script with file path input")
parser.add_argument("--file_path", type=str, required=True, help="Path to the input file")
args = parser.parse_args()
run(args.file_path)

