量化索引:Scalar Quantization 标量量化
本文转载:https://yongyuan.name/blog/scalar-quantization.html
本意为了归纳总结向量索引相关的知识,方便日后翻阅,自己做了些许的修改~
背景
在工作中遇到这样一个场景:通过多模态学习到的 64 维 video embedding,在搜索竞拍的时候,需要实时取到前 K(K>=300)个结果对应得的 video embedding,由于模型比较大,这个 video embedding,不支持实时计算,而是在视频上传时候,就被计算好。工程架构对存储和读取性能是有要求的,既不能直接将这 664 维 embedding 直接写到 kiwi(redis改造后的数据库)里面。
这个问题,可以简化为:有没有一种量化方法,将一个 d 维 float 型向量,encode 为一个 d 维 int8 型的向量,这个 d 维 int8 型的向量经过 decode 后,与原始向量的误差尽可能小?这样一来,存储空间降低为原来的 1/4 倍,并且读取 int8 的性能比 float 型会快很多。答案是肯定的,这就是本篇博文要介绍总结的 Scalar Quantization。
Scalar Quantization,即标量量化。关于 Scalar Quantization,网上资料比较多(Google)但小白菜在查过很多资料后,发觉能把 Scalar Quantization 向量量化过程讲清楚,并且还能剖析 faiss 中实现的 Scalar Quantization。为了方便后面的同学理解,小白菜结合自己对 Scalar Quantization 原理与实现,做了整理。
Scalar Quantization 原理
Scalar Quantization 标量量化,分为 3 个过程:
- training 过程,主要是训练 encode 过程,需要的一些参数,这些的参数,主要是每 1 维对应的最大值、最小值;
- encode 过程,将 float 向量量化为 int8 向量(int8 是其中一种数据压缩形式,还有 4 比特之类的,这里主要以 8 比特说明原理)
- decode 过程,将 int8 向量解码为 float 向量;
为了更好的说明 Scalar Quantization 的原理,小白菜画了 Scalar Quantization 标量量化原理框图,如下图所示:
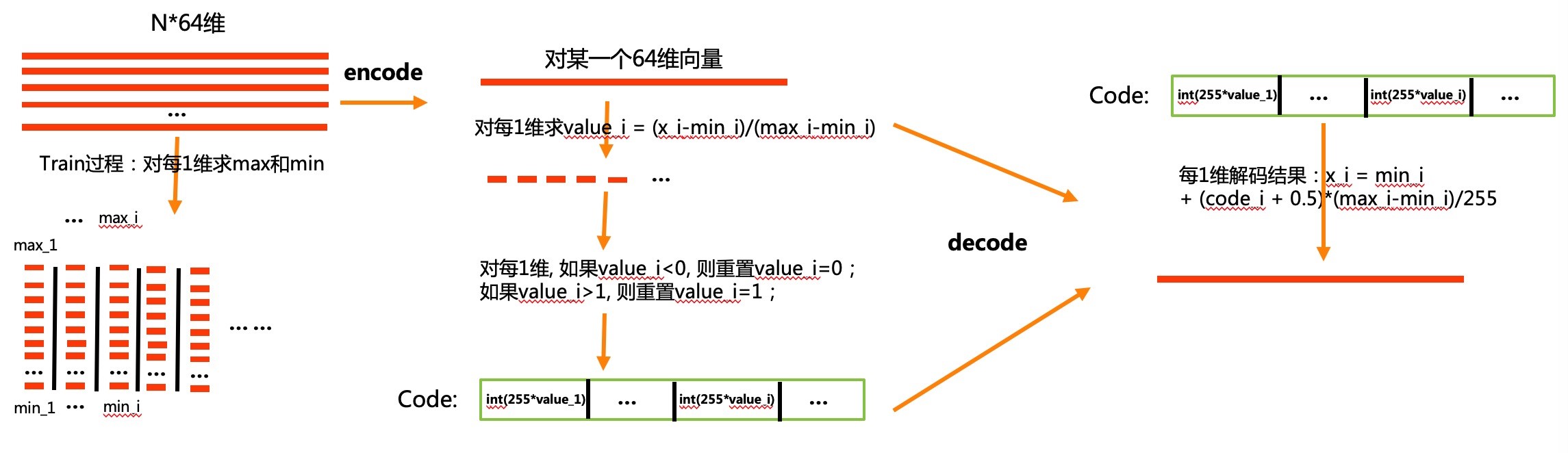
整个 Scalar Quantization 过程,其实是很容易理解的,下面对训练、编码和解码做些说明。
训练过程
Scalar Quantization 训练过程,如上图最左边所示,从样本中随机采样出 N 个样本后,训练过程主要是得到 N 个样本中每 1 维的最大值、最小值。得到最大值、最小值后,将它们保存下来即可。实际在训练的时候,N 能大的时候,尽量大点。
N 个样本中每 1 维的最大值、最小值:如上图所示,将 64 维度向量切成 64 份,求 N 个向量,在第 i 维度的最大值、最小值。
编码过程
Scalar Quantization 在编码的时候,对于一个 d 维的待编码的 float 型向量 $x=\lbrace x_1,x_2,…,x_d \rbrace$,编码过程主要包含如下步骤:
- 对每 1 维,求 $value_i=\frac{x_i-min_i}{max_i-min_i}$;
- 对每 1 维,如果 $value_i<0$,则 $value_i$ 重置为 0;如果 $value_i>1$,则 $value_i$ 重置为 1。这里主要是对边界情况做异常处理,理论情况下,是不会出现$value_i<0$ 或者 $value_i>0$ 的情况;
- 对每 1 维,对应的编码 $code_i=int(255*value_i)$。为什么 255?可以思考下;
归一化:对于每个维度,将原始值映射到 [0, 1] 范围内
截断:将归一化后的值截断到 [0, 1] 范围内
量化:将截断后的值乘以 255 并进行取整,得到最终的编码值
“255”:8 位整数,量化范围为 [0, 255]
整个过程,如上图中的中间图所示。这样就完成了 float 型向量 $x=\lbrace x_1,x_2,…,x_d \rbrace$ 的编码,将向量的每 1 维,都变成了一个用 int8 表示的整型数据,也就是对应的 Scalar Quantization 的编码。
解码过程
Scalar Quantization 解码过程,是解码的逆过程。解码过程步骤如下:
- 对每 1 维,$x_i=min_i+\frac{(code_i+0.5)*(max_i-min_i)}{255}$,通过该式子,即可完成对第i维的解码。留个问题:为啥 $code_i$ 需要加上 0.5?
加 0.5 的作用是将这两种误差平均到每个取值区间内
例如,对于取值区间 [0, 1],如果不对编码值加 0.5,那么所有落在该区间内的浮点型数据都会被映射到同一个离散值 0。这会导致量化误差过大。而加 0.5 后,所有落在该区间内的浮点型数据都会被映射到 0 或 1,并将量化误差平均到这两个离散值上。
Scalar Quantization 实现
Scalar Quantization 的训练、编码、解码实现,可以参考小白菜的实现scalar_quantization。训练过程,就是计算各维最大值、最小值,自己实现的话,具体可以看 L68-L97 。使用faiss的话,如下:
faiss::IndexScalarQuantizer SQuantizer(d, faiss::ScalarQuantizer::QT_8bit, faiss::METRIC_L2);
SQuantizer.train(num_db, xb);
// SQuantizer.add(num_db, xb);
faiss::write_index(&SQuantizer, model_path.c_str());
在 sq_train.cpp 里面,对比了自己实现的训练过程结果和 faiss 训练出来的结果,训练出来的参数结果,两者是一致的。
faiss encode 的实现,如 L328 所示:
void encode_vector(const float* x, uint8_t* code) const final {
for (size_t i = 0; i < d; i++) {
float xi = 0;
if (vdiff != 0) {
xi = (x[i] - vmin) / vdiff;
if (xi < 0) {
xi = 0;
}
if (xi > 1.0) {
xi = 1.0;
}
}
Codec::encode_component(xi, code, i);
}
}
其中 vdiff = max - min。faiss decode 的实现,如 L344 所示:
void decode_vector(const uint8_t* code, float* x) const final {
for (size_t i = 0; i < d; i++) {
float xi = Codec::decode_component(code, i);
x[i] = vmin + xi * vdiff;
}
}
针对小白菜 Scalar Quantization,小白菜实现的编解码过程,同时提供了 faiss 实现的接口调用,也提供了自己实现的接口调用,具体可以阅读 int8_quan.cc。
另外,关于 Faiss 实现的 decode 接口,由于采用了多线程方式,在实际使用的时候,当请求解码的数据量不够大的时候,多线程的方式,性能反而下降,具体可以看这里提到的Issue: Scale quantization decodes does not fast。

