Linux网络性能指标
性能指标
- 带宽,表示链路的最大传输速率,单位通常为 b/s(比特/秒)
- 吞吐量,表示单位时间内成功传输的数据量,单位通常为 b/s(比特/秒)或者 B/s(字节/秒)。吞吐量受带宽限制,而吞吐量/带宽,也就是该网络的使用率
- 延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同的涵义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT)
- PSS,是 Packet Per Second(包/秒)的缩写,表示以网络包为单位的传输速率。PSS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响
另外,网络的可用性(网络能否正常通信)、并发连接数(TCP 连接数量)、丢包率(丢包百分比)、重传率(重新传输的网络包比例)等也是常用的性能指标。
网络配置
使用命令 ifconfig 或者 ip 查看
1 | $ ifconfig eth1 |
第一,网络接口的状态标志。ifconfig 输出 RUNNING,或者 ip 输出中的 LOWER_UP,都表示物理网络是连通,即网卡已经连接到了交换机或者路由器中。如果你看不到它们,通常表示网线被拔掉了。
第二,MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同(比如是否使用了 VXLAN 等叠加网络),你可能需要调大或者调小 MTU 的数值。
第三,网络接口的 IP 地址、子网以及 MAC 地址。这些地址都是保障网络功能正常工作所必须的,你需要确保配置正确。
第四,网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:
- errors 表示发生错误的数据包数,比如校验错误、帧同步错误等
- dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包
- overruns 表示超限数据丢包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包
- carrier 表示发生 carrirer 错误的数据报数,比如双工模式不匹配、物理电缆出现问题等
- collisions 表示碰撞数据包数
嵌套字信息
使用 netstat 或 ss 来表示嵌套字、网络栈、网络接口以及路由表的信息
1 | $ netstat -nlp | head -n 3 |
其中,接收队列(Recv-Q)和发送队列(Send-Q)需要关注,它们通常是 0。当你发现它们不是 0 时,说明有网络包的堆积发生
当嵌套字处于连接状态(Established)时,
- Recv-Q 表示嵌套字缓冲还没有被应用程序取走的字节数(即接收队列长度)
- Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)
当嵌套字处于监听状态(Listening)时,
- Recv-Q 表示当前全连接队列(accept 队列)长度
- Send-Q 表示全连接队列的最大长度
协议栈统计信息
使用 netstat 或 ss 命令
1 | $ netstat -s |
网络吞吐 和 PPS
使用 sar 命令,加上 -n 参数,可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP 等
1 | $ sar -n DEV 1 |
- rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包/秒
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/s
- rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包/秒
带宽可以用 ethtool 来查询,它的单位通常是 Gb/s 或者 Mb/s(千兆网卡或者万兆网卡的单位都是 bit)
1 | $ ethtool enp4s0f0 | grep Speed |
连通性和延时
使用命令 ping,来测试远程主机的连通性和延时(基于 ICMP 协议)
如下,测试本机到 baidu.com 这个地址的连通性和延时
1 | $ ping -c3 baidu.com |
ping 的输出,可以分为两部分:
- 每个 ICMP 请求的信息,包括 ICMP 序列号(icmp_seq)、TTL(生存时间,或者跳数)以及往返延时
- 三次 ICMP 请求的汇总
C10K和C100K问题
C10K
C10K 代表同时处理 10000 个请求
从资源上来说,对 2GB 内存和千兆网卡的服务器来说,同时处理 10000 个请求,只要每个请求处理占用不到 200KB(2GB/10000)的内存和 100Kbit(1000Mbit/10000)的网络带宽就可以。
从软件上来看,主要是网络 I/O 模型的问题,在 C10K 之前,Linux 主要是同步阻塞的方式,每个请求都分配一个进程或者线程,而 10000 个进程或者线程的调度、上下文切换和内存,都可能成为瓶颈。
需要解决的问题:
- 怎样在一个线程内处理多个请求,也就是要在一个线程内响应多个网络 I/O?
I/O 模型优化
异步、非阻塞 I/O 的思路:I/O 多路复用
两种 I/O 时间通知的方式:水平触发和边缘触发
水平触发:只要文件描述符可以非阻塞地执行 I/O,就会触发通知。也就是说,应用程序可以随时检查文件描述符地状态,然后再根据状态,进行 I/O 操作。
边缘触发:只有在文件描述符的状态发生改变(也就是 I/O 请求达到)时,才会发送一次通知。这时候,应用程序需要尽可能多地执行 I/O,知道无法继续读写,才可以停止。如果 I/O 没执行完,或者因为某种原因没来得及处理,那么这次通知也就丢失了
- 第一种,使用非阻塞 I/O 和水平触发通知,比如使用 select 或者 poll
- 第二种,使用非阻塞 I/O 和边缘触发通知,比如 epoll(在 select 和 poll 基础上进行优化)
- 第三种,使用异步 I/O(Asynchronous I/O,简称为 AIO)
工作模型优化
I/O 多路复用有两种主要的工作模式:
第一种:主进程 + 多个 worker 子进程(比如 nginx),主要流程是:
- 主进程执行 bind() + listen() 后,创建多个子进程;
- 在每个子进程中,都通过 accept() 或 epoll_wait() ,来处理相同的套接字
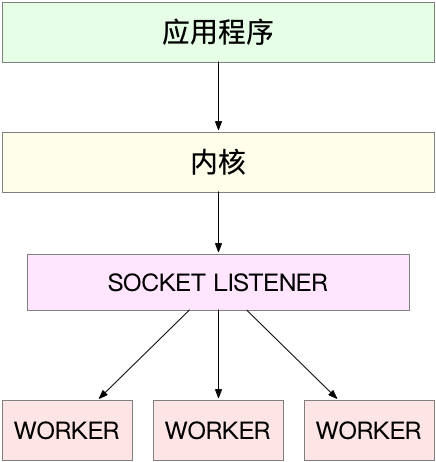
注意:accept() 和 epoll_wait() 调用,还存在一个惊群的问题(当网络 I/O 事件发生时,多个进程被同时唤醒,但实际上只有一个进程来响应这个事件,其他被唤醒的进程都会重新休眠)
为了避免惊群问题,Nginx 在每个 worker 进程中,都会增加一个全局锁(accept_mutex)。这些 worder 进程需要首先竞争到锁,只有竞争到锁的进程,才会加入到 epoll 中,这样就确保只有一个 worker 子进程被唤醒
第二种:监听到相同端口的多进程模型,所有的进程都监听相同的端口,有各自的套接字,开启 SO_REUSEPORT 选项(Linux 3.9+ 才支持),由内核负责将请求负载均衡到这些监听进程中去
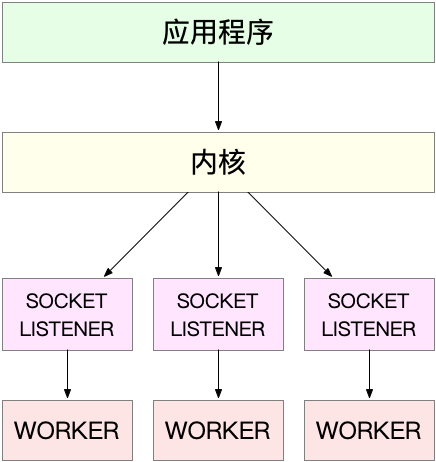
C1000K
C1000K 代表同时 100w 个请求
- 从物理资源上来说,100 万个请求需要大量的系统资源
- 内存:假设每个请求需要 16KB 内存的化,那么总共就需要大约 15GB 内存
- 带宽:假设只有 20% 活跃连接,即使每个连接只需要 1KB/s 的吞吐量,总共需要 200000 * 8 / 1024 / 1024 = 1.6 Gb/s 的吞吐量,千兆网卡已经不能够满足,需要配置万兆网卡
- 从软件资源上来说,大量的连接也会占用大量的软件资源,比如文件描述符的数据、连接状态的跟踪(CONNTRACK)、网络协议栈的缓存大小(比如套接字读写缓存、TCP 读写缓存)等等,也会带来大量的中断处理
优化:在 I/O 多路复用的基础上,需要多队列网卡、硬中断负载均衡、CPU 绑定、RPS/RFS(软中断负载均衡到多个 CPU 核上),以及将网络包的处理卸载(Offload)到网络设备(如 TSO/GSO、LRO/GRO、VXLAN OFFLOAD)等各种硬件和软件的优化。
C10M
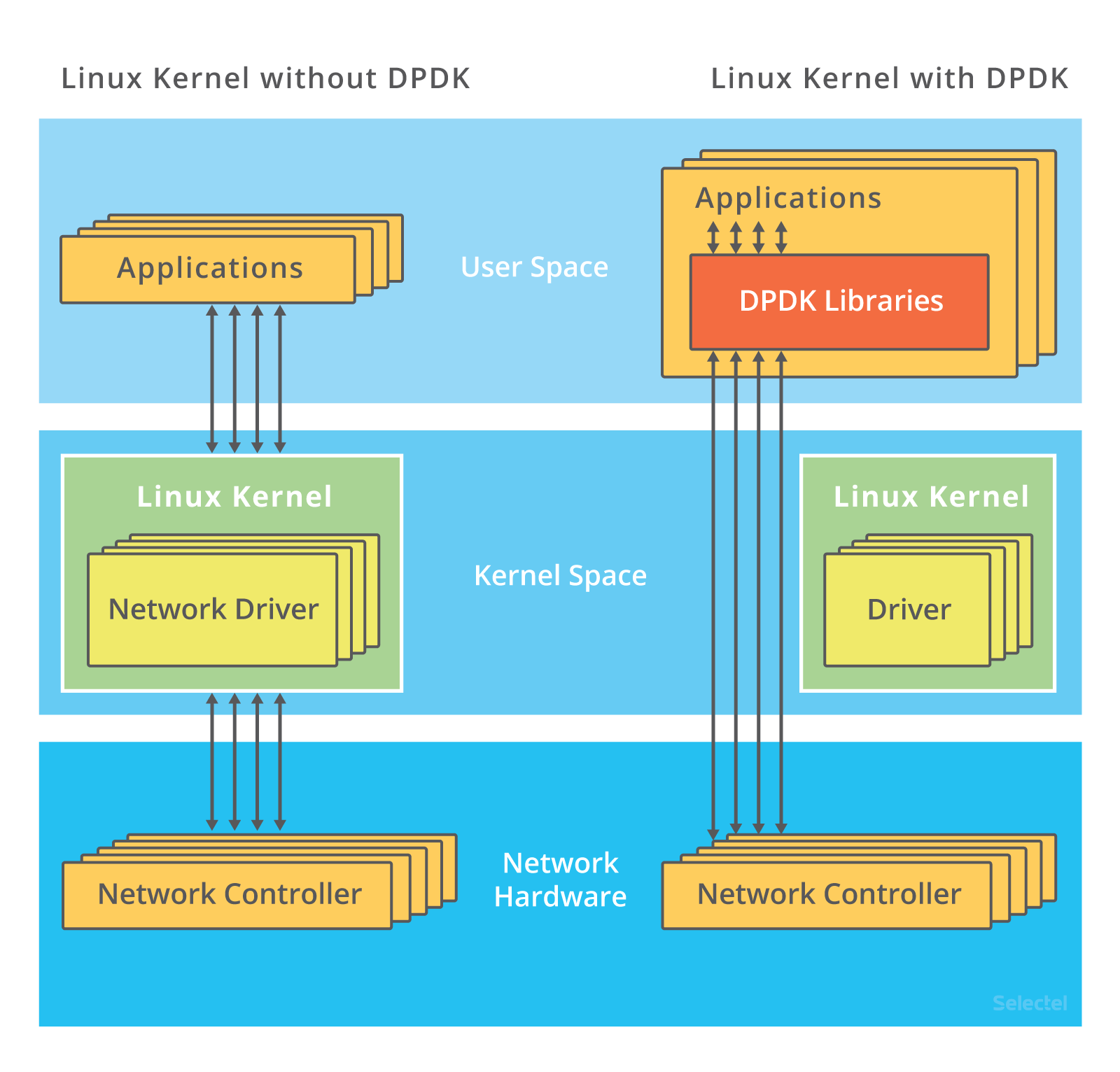
同时有 1000w 个请求,解决方法是跳过内核协议栈,将网络包直接发送到要处理的应用程序
第一种机制:DPDK(Data Plane Development Kit),用户网络的标准,跳过内核协议栈,直接由用户态进程通过轮询的方式来处理网络请求
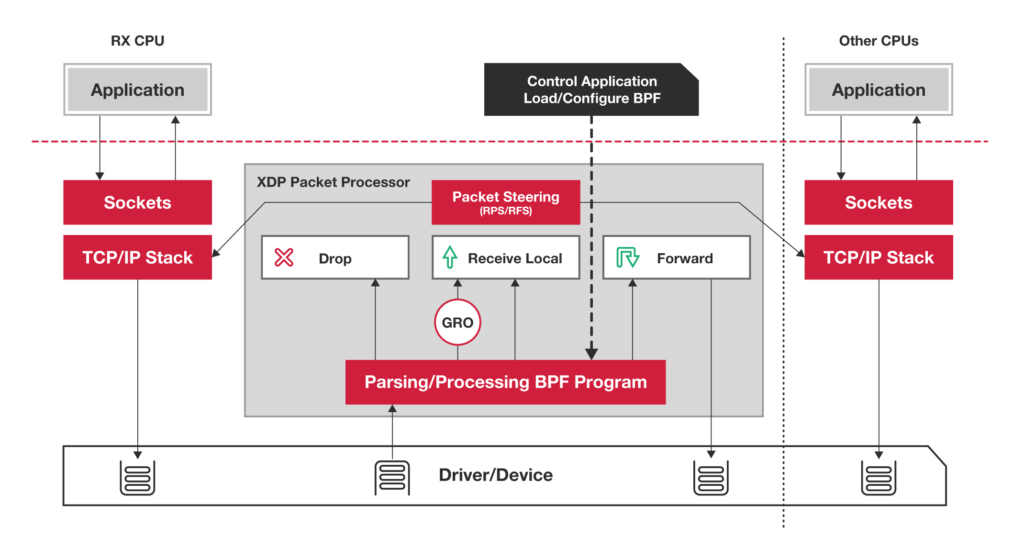
第二种机制:XDP(eXpress Data Path),Linux 内核提供的一种高性能网络数据路径,它允许网络包,在进入内核协议栈之前,就进行处理
怎么评估系统的网络性能
各协议层的性能测试
转发性能
hping3 工具,测试网络包的处理能力: hping3 手册
TCP/UDP 性能
iperf 网络性能测试工具: iperf 手册
iperf3 是 iperf 的重写版本,一些常用参数:
| 主要参数 | 参数说明 |
|---|---|
| -s | 服务端专用参数,表示 iperf3 以服务端模式运行 |
| -c | 客户端专用参数,表示 iperf3 以客户端模式运行 |
| -i | 设置每次报告之间的时间间隔,单位为秒 |
| -p | 服务端:指定服务端监听的端口,默认为 5201,同时监听 TCP/UDP。 客户端:指定客户端连接服务端的端口,默认为 5201。如果同时有 -u 参数,表示通过 UDP 发起连接,否则默认使用 TCP 连接 |
| -u | 表示使用 UDP 协议发送报文。若不指定该参数则表示使用 TCP 协议 |
| -l | 设置读写缓冲区的长度。通常测试包转发性能时建议该值设为 16,测试带宽时建议该值设为 1400 |
| -b | UDP 模式使用的带宽,单位 bit/s |
| -t | 设置传输的总时间。iperf3 在指定时间内,重复发送指定长度数据包的时间,默认值为 10 秒 |
| -A | 设置 CPU 亲和性,可以将 iperf3 进程绑定对应编号的逻辑 CPU,避免 iperf3 进程在不同的 CPU 间被调度 |