本文是一篇英文翻译转载文章,主要介绍了 javaprofiler 的工作原理。
原英文链接:https://psy-lob-saw.blogspot.com/2016/02/why-most-sampling-java-profilers-are.html
这篇文章建立在之前的一篇关于安全点的文章的基础上。如果你没有读过它,你可能会感到迷茫和困惑。如果你读过这篇文章,仍然感到迷茫和困惑,并且您确定这种感觉与当前的问题有关(而不是生存危机),请继续提问。
那么,既然我们已经确定了什么是安全点,那么:
- 安全点轮询分散在相当多的任意点(取决于执行模式,主要是在未计数的循环后端或方法返回/入口)
- 将 JVM 带到全局安全点的成本很高
我们已经掌握了所有需要的信息,可以得出结论,通过在安全点采样来进行剖析可能有点糟糕。这对于某些人来说并不奇怪,但是这个问题在最常见的分析器中是存在的。根据 RebelLabs 的调查,以下是详细情况:
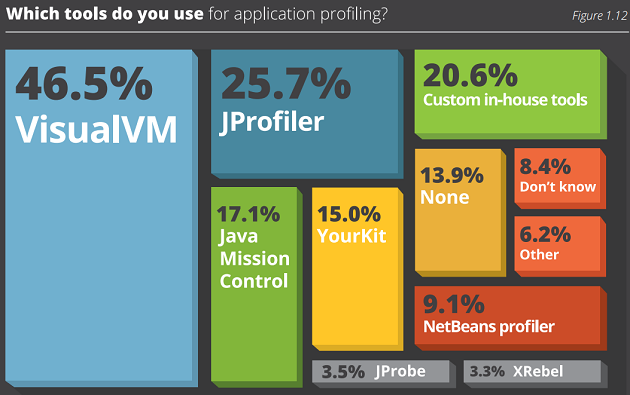
VisualVM、NB Profiler(同上)、YourKit 和 JProfiler 都提供了一个 CPU 分析器,可以在安全点进行采样。鉴于这是一个相当常见的问题,让我们深入研究一下。
采样执行探查器如何工作 (理论上)
抽样分析器应该通过收集应用程序在不同时间点所处位置的样本,来接近应用程序中“花费的时间”的分布。在每个样本中收集的数据可以是:
- current instruction
- current line of code
- current method
- current stack trace
数据可以为单个线程收集,也可以为每个样本中的所有线程收集。我们需要保存哪些数据才能进行有效的采样?
然而,要使采样结果与完整(未采样)分析结果相媲美,必须满足以下两个条件。
首先,我们必须拥有大量样本才能获得具有统计意义的结果。例如,如果一个分析器在整个程序运行过程中只收集了一个样本,那么该分析器会将程序执行时间的 100% 分配给它进行采样的代码,而将 0% 分配给其他所有代码。[…]
其次,分析器应该以相同的概率对程序运行中的所有点进行采样。如果分析器不这样做,它的分析结果最终会出现偏差。例如,假设我们的分析器只能对包含调用的方法进行采样。即使不包含调用的方法可能占据了程序执行时间的很大一部分,该分析器也不会将执行时间分配给这些方法。
——摘自《评估 Java 分析器的准确性》,我们稍后会回到这篇文章。
这听起来很简单,对吧?
一旦我们有了大量的样本,我们就可以构建一个热方法列表,甚至是这些方法中的代码行(如果样本报告了它),我们可以查看分布在调用树上的样本(如果收集了调用跟踪)并且度过一段美好的时光!
通用商业 Java 采样执行分析器如何工作
好吧,我可以在这里从不同的解决方案进行逆向工程,或者通读开源代码库,但是我会提供一些没有支持的猜测,如果你知道更多的话,可以自由地告诉我。通用分析器依赖于 JVMTI(JVM Tool Interface) 规范,所有 jvm 都必须满足这一规范:
- JVMTI 仅提供安全点采样堆栈跟踪收集选项(调用线程的 GetStackTrace 不需要安全点,但对分析器来说用处不大;在 Zing 中,对其他线程调用 GetStackTrace 仅会将该线程带到安全点)。因此,希望其工具能在所有 JVM 上运行的厂商只能采用安全点采样方式。
- 无论你是在对单个线程进行采样还是对所有线程进行采样(至少在 OpenJDK 上是这样,Zing 略有不同,但作为分析工具供应商,你应假设使用的是 OpenJDK)。我所查看过的所有分析工具都采用对所有线程进行采样的方式。据我所知,它们也不会限制收集的堆栈深度。这相当于以下 JVMTI 调用:JvmtiEnv::GetAllStackTraces (0,&stack_info,&thread_count)
- 因此,这相当于:设置一个定时线程,每隔 ‘sampling_interval’ 时间触发一次,并收集所有的堆栈跟踪信息。
这有几个坏处,其中一些可以避免的:
- 采样分析器需要采样,因此通常会将采样频率设置得相当高(通常为每秒 10 次,或每 100 毫秒一次)。设置
-XX:+PrintGCApplicationStoppedTime并查看这引入了什么样的暂停时间是有指导意义的。几毫秒的暂停并不罕见,但具体情况具体分析(取决于线程数、堆栈深度、TTSP 等)。每 100 毫秒暂停 5 毫秒意味着分析器会引入 5% 的开销(实际损失可能比这更严重)。通常可以通过设置更长的间隔来控制损失,但这也意味着你需要更长的分析周期才能获得有意义的样本计数。 - 从所有线程收集完整的栈跟踪意味着你的安全点操作成本是开发的。你的应用程序拥有的线程越多(想想应用程序服务器、SEDA 架构、大量线程池等),你的栈跟踪越深(想想 Spring 和 Co.),你的应用程序等待单个线程来回采集名称和填写表单的时间就越长。据我所知,当前的分析器对此毫无帮助。如果你正在构建自己的分析器,那么对数量设置限制似乎是明智的,这样你就可以控制开销。JVMTI 功能允许你查看当前线程列表,如果少于 100 个,你可以对所有的线程进行采样,否则可以随机选择 100 个线程的子集进行采样。也许更倾向于采样那些实际在做某事的线程,而不是那些整天被阻塞的线程,这是有道理的。
- 仿佛这一切还不够糟糕似的,其实我感觉在安全点进行抽样似乎也有些毫无意义
第 1 点和第 2 点是关于剖析开销的,这基本上是关于成本的。在我之前关于安全点的文章中,我查看了这些成本,所以没有必要重复这个练习。对于良好的剖析信息,成本可能是可以接受的,但正如我们将看到的,这些信息并不那么重要。
第 3 点需要解释,所以我们开始寻找其含义。
安全点采样:理论
那么,在安全点进行采样意味着什么?这意味着只运行代码中的安全点轮询是可见的。考虑到热代码可能是由 C1/C2 (客户端/服务器编译器) 编译的,我们减少了方法退出和未经计数的循环备份的采样机会。这导致了所谓的安全点排查现象,即采样性能分析器的采样偏向于下一个可用的安全点轮询位置(这违反了上面列出的第二个标准“性能分析器应该以相对概率对程序运行中的所有点进行采样”)。
这乍听起来可能没那么糟糕,所以让我们通过一个简单的例子来看看哪一行收到了责备。
注意:在以下所有示例中,我将使用 JMH 作为测试工具,并使用 “CompilerControl” 注释来防止内联。这就使我能够控制编译单元的限制,这可能看起来很残酷、不寻常,或者至少是不公平的。在“野生”环境中,内敛决策受到很多因素的影响,(在我看来)将它们视为任意的(在几个编译器/JVM供应商/命令行参数等的手中)是安全的。内联可能是“所有优化之母”,但它在这方面是一个反复无常且狡猾的长辈。
让我们看一个简单的例子:
1 |
|
这是一个容易思考的例子。我们可以通过改变数组的大小来控制方法中的工作量。我们知道技术循环中没有安全点轮询(通过查看汇编输出验证),因此理论上,上述方法在方法退出时将有一个安全点。问题是,如果我们让上述方法内联,方法的末尾安全点轮询将消失,而下一轮轮询将在测试循环中:
1 | public void meSoHotInline_avgt_jmhStub(InfraControl control, RawResults result, |
因此,如果测量方法没有内联,预期它会受到指责似乎是合理的,但如果它确实内联了,我们可以预期测量方法会受到指责。对吧?非常合理,但有点偏差。
安全点采样:现实
在这篇 2010 年发表的精彩论文《评估 Java 性能分析器的准确性》中,作者们讨论了安全点偏差。他们认识到,不用的 Java 性能分析器会在同一基准中识别不同的热点,并深入研究其原因。他们没有建立一些一直热点的基准,并利用这些基准来理解安全点偏差性能分析器所看到的内容。他们指出:
如果我们知道程序运行的“正确”分析结果,我们就可以根据这个正确的分析结果来评估分析器。不幸的是,大多数情况下并不存在“正确”的分析结果,因此我们无法确切地确定分析器是否产生了正确的结果。
那么,如果我们构建一个已知的工作负载…… 这些分析器会看到什么呢?
我们将使用 JMH 安全点偏置性能分析器 “-prof stack” 来研究这一点。它很像 JVisualIVM 提供的相同代码的性能分析,而且对于这项研究来说,它看起来更加方便。注意:在接下来的部分中,我是用术语 sub-method 来描述从另一个方法调用的方法。例如,如果方法 A 调用了方法 B,则 B 是 A 的子方法。也许存在更好的术语,但这就是我在这里的意思。
如果我们运行上面的示例,我们会得到两行不同的热线代码 (使用 -prof stack:detailLine=true 运行):
1 | # Benchmark: safepoint.profiling.SafepointProfiling.meSoHotInline |
在实际的热点方法中没有这种情况。似乎方法退出安全点并不被认为是其自身方法的指示,而是被认为是调用它的代码行的指示。因此,强制测量中的方法不内联意味着测量循环中的调用代码行,而让它内联则意味着循环的后端受到责备。同样,似乎一个未计数的循环安全点轮询也被认为是其自身方法的指标。
我们可以推断(但不一定是正确的),当看到这种没有代码行数据的分析结果时,一个热点方法表示:
- 某些非内联子方法是热点
- 在一个未计数的循环中,某些代码(自用方法?内联子方法?非内联子方法?)是热点
拥有一行代码数据可以帮助消除上述情况的歧义,但作为一行代码数据并不是很有用。一行热点代码可能表示:
- 该行有一个方法调用:从该行调用的方法(或者它的内联子方法)是热点
- 该行是一个循环的后端:这个循环中的一些代码(包括内联子方法)是热点
这看起来有用么?别抱太大希望。
因为我们通常不知道哪些方法被内联了,这可能会有点令人困惑(如果你想知道,可以使用 -XX:+PrintInlining,但是要注意,内敛决策可能会随着运行而变化)
注意间距
如果上述规则成立,你可以通过检查执行树中被指责节点下方的代码来使用安全点偏差性分析。换句话说,这将意味着一个热点方法表名热点 diamagnetic 可能位于该代码或其调用的方法中的某处。了解这一点会很有帮助,这个分析可以作为一些有效挖掘的起点。但遗憾的是,这些规则并不总是成立。它们忽略了一个事实,即热点代码可能位于指定的安全点轮询和之前的轮询之间的热河位置。参考以下示例:
1 |
|
显然,在调用 setResult 之前,时间是在循环中度过的,但分析结果会归咎于 setResult。setResult 没有任何问题,除了它调用方法不是内联的,这为我们的分析器提供了归咎的机会。这证明了安全点轮询机会呈现给用户代码的随机性,并表明热代码可能位于当前安全点轮询和上一个安全点轮询之间的任何位置。这意味着,如果不知道上一个安全点轮询的位置,那么在安全点偏向的分析结果中,热方法/代码行可能会产生误导。请考虑以下示例:
1 |
|
分析器暗示调用者指向了堆栈下方 9 层的一个廉价方法,但真正的罪魁祸首是最顶层方法的循环。需要注意的是,内联会阻止方法显示,但非内联的框架只会在返回时打破安全点之间的间隙(无论如何,在 OpenJDK 上如此。这取决于供应商和用户的想法。例如,Zing 将方法级别的安全点放在入口处,我不确定 J9 对此持何种立场。这并不是说一种方法比另一种更好,只是说位置是任意的)。这就是为什么非内联且位于堆栈更高位置的 setResult6 没有显示的原因。
总结:它有什么用
如上所述,安全点采样分析器可能会对应用程序中的热点代码位置产生严重不准确的判断。这使得对“运行中”线程的衍生观察变得相当可疑,但至少对哪些线程正在运行的观察是正确的。这并不意味着它们完全没有用,有时候我们只需要一个正确的方向提示,就能进行一些好的分析,但这里也存在浪费时间的巨大风险。虽然在解释器中运行的代码样本不会受到安全点偏差的影响,但这并不是很有用,因为热点代码很快就会被编译。如果你的热点代码还在解释器中运行,那么你有比安全点偏差更大的问题需要解决……
阻塞线程的堆栈跟踪是准确的,因此 “Waiting” 状态分析对于发现阻塞代码的性能瓶颈非常有用。如果阻塞方法是你性能问题的根源,那么这一分析结果会是一个很重要的线索。
外面还有更好的选择!例如:
- Java Mission Control
- Solaris Studio
- Honest-Profiler
- Perf + perf-map-agent (or perfasm if your workload is wrapped in a JMH benchmark)
没有哪种工具是完美的,但上述所有工具在识别 CPU 时间花费方面都还不错。